8. Infrastruttura per servizi REST¶
Il presente documento descrive, da un punto di vista tecnico, l’implementazione di una infrastruttura di Servizi Rest che permette la fruibilità ad altre applicazioni informatiche dei dati amministrativo- contabili gestiti dall’applicativo SIGLA. Il documento inizialmente presenta una dettagliata analisi dei requisiti richiesti; in seguito evidenzia una serie di implementazioni possibili riepilogate in una tabella comparativa ed infine analizza nel dettaglio la soluzione adottata, presentando una breve panoramica della tecnologia impiegata ed illustrando gli aspetti funzionali, architetturali ed implementativi della soluzione. La realizzazione del sistema è stata avviata nel 2015 e si è conclusa nel 2016.
8.1. Elenco degli acronimi¶
- SIGLA: Sistema Informativo per la Gestione delle Linee di Attività
- HTTP: HyperText Trasfer Protocol
- HA: High Availability
- REST: Representational State Transfer
- ROA: Resource Oriented Architecture
- JVM: Java Virtual Machine
- URI: Uniform Resource Identifier
- URL: Uniform Resource Locator
- MIME: Multipurpose Interact Mail Extension
- JSON: Javascript Object Notation
- XML: eXtensible Markup Language
- MVC: Model-View-Controller
- TCP: Transmission Control Protocol
- SOA: Services Oriented Architecture
- SOAP: Simple Object Access Protocol
- WDSL: Web Services Description Language
- W3C: World Wide Web Consortium
8.2. Introduzione¶
Come è noto, l’innovazione tecnologica e l’utilizzo di sistemi informativi efficienti contribuiscono validamente a promuovere la crescita organizzativa e a migliorare la funzione amministrativa e la governance. Oggi l’ottimizzazione, la maggiore efficienza, la trasparenza, l’economicità del lavoro nella pubblica amministrazione sono al centro del dibattito pubblico: in tale contesto le ICT, se debitamente utilizzate, possono concorrere efficacemente a snellire i procedimenti amministrativi e a ridurre i costi, consentendo pertanto di destinare le risorse così risparmiate ad altre iniziative, spesso bloccate o rallentate dalla carenza di personale o dall’insufficienza degli investimenti. L'evoluzione dei sistemi informativi, grazie alla crescente integrazione tra le varie applicazioni software, consente di sfruttare al meglio i dati, che divengono pertanto, sempre di più, un elemento essenziale per la vita delle organizzazioni. Tanto più questo è vero per un ente di ricerca come il Consiglio Nazionale delle Ricerche in cui i dati hanno una valenza duplice, sotto il profilo del patrimonio della conoscenza e insieme sotto quello amministrativo e organizzativo. In tale contesto appare fondamentale avere un accesso sempre più rapido e aggiornato alle informazioni. Si comprende quindi perché SIGLA, il sistema informativo amministrativo-contabile da tempo in uso presso il CNR, abbia acquistato via via un ruolo sempre maggiore per la pianificazione, l’organizzazione, la gestione e la consuntivazione delle risorse dell’Ente. È diventato perciò decisivo poter mettere a disposizione degli altri sistemi informativi CNR il patrimonio di dati e informazioni che SIGLA gestisce. A questo scopo si è deciso di creare uno strato software “OPEN SIGLA”, che permetta appunto a SIGLA di rendere disponibili e utilizzabili i propri dati ai sistemi informativi dell’Ente che ne facciano richiesta, superando le criticità della loro eterogeneità. OPEN SIGLA, seguendo le specifiche ROA, garantisce infatti l’accesso non solo agli utenti finali ma anche ad altri sistemi e applicazioni software. In questo modo, le risorse risultano accessibili a qualsiasi applicativo che ne sia autorizzato, senza che questo debba possedere la conoscenza della specifica implementazione e del tipo di piattaforma utilizzata da SIGLA. In particolare, l’applicazione rende disponibili i dati delle consultazioni presenti in SIGLA attraverso i REST, garantendo l’interoperabilità con qualunque altro software applicativo.
8.3. La genesi di OPEN SIGLA¶
Durante la progettazione dell’applicativo “Gestione Missioni”, si è evidenziata l’importanza dei dati presenti nell’applicativo SIGLA necessari per l’utilizzo della nuova suite:
- Anagrafica Centri di Spesa;
- Anagrafica Unità Organizzative;
- Anagrafica Centri di Responsabilità;
- Anagrafica Progetti;
- Anagrafica GAE;
- Anagrafica Capitoli di Bilancio;
- Elenco Impegni con relative disponibilità;
- Anagrafica Terzi;
- Tipo Missione;
- Tipo Spesa Missione;
- Inquadramento
sorta l’esigenza di consultare i dati presenti in SIGLA in tempo reale, garantendo la sicurezza ed i filtri alla visualizzazione, usufruendo delle informazioni in modo semplice, senza gravare sulle performance di utilizzo di SIGLA.
Di conseguenza, abbiamo pensato ad una soluzione strutturata che potesse rispondere alle esigenze del nuovo applicativo “Gestione Missioni” e ad eventuali necessità provenienti dai vari sistemi informatici utilizzati a supporto dell’attività dell’Ente. Il nome che abbiamo dato alla nuova soluzione applicativa è OPEN SIGLA.
8.4. Requisiti¶
Da un’attenta analisi della problematica e delle esigenze funzionali sono emersi i seguenti requisiti minimi a cui la nuova applicazione deve rispondere:
Tempo reale
I dati devono essere aggiornati, in modo che l’applicativo che fruisce dei dati di SIGLA utilizzi sempre gli ultimi dati disponibili, ad esempio:
Verifica della disponibilità di un impegno; Visualizzazione della disponibilità dei GAE.
Abilitazioni
I dati visualizzabili devono essere filtrati a seconda dell’utente che ne chiede la consultazione, ad esempio:
Un utente dell’Istituto di Informatica e Telematica (IIT) deve vedere solo gli impegni propri e non quelli di altri istituti;
Un utente amministrativo, abilitato all’inserimento dell’ordine di missione, non necessariamente deve aver accesso ad altre operazioni amministrative-contabili come consultare i versamenti delle ritenute.
Velocità nel recupero delle informazioni
Le informazioni devono essere disponibili rapidamente.
Facilità nella lettura delle informazioni
I dati devono essere facilmente fruibili dall’applicativo che ne fa richiesta limitando al minimo i tempi nello sviluppo dell’implementazione di integrazione con OPEN SIGLA.
Utilizzo delle ultime innovazioni tecnologiche
L’implementazione deve essere di facile manutenzione e deve durare nel tempo per ridurre l’obsolescenza del software.
Implementazione facile e rapida degli altri sistemi
L’implementazione software del sistema applicativo che desidera usufruire dei dati di SIGLA deve essere di facile e rapida realizzazione.
Sicurezza
I dati devono essere recuperati mantenendo un elevato standard di sicurezza.
Prestazioni
Le richieste di informazioni provenienti dai vari sistemi non devono compromettere le prestazioni e i tempi di risposta di SIGLA.
8.4.1. Accesso ai Servizi¶
Per fornire l'accesso ai servizi bisogna che l'amministratore delle utenze dell'istituto, provveda alla creazione dell'utenza in SIGLA attraverso la funzione specifica ed in seguito assegni il ruolo REST_SIGLA all'utenza creata, tramite la funzione dei Ruoli.
8.5. Soluzioni possibili¶
Per permettere la consultazione dei dati di SIGLA sul web sono possibili diverse soluzioni:
- Copia delle tabelle contenenti i dati di interesse di SIGLA nell’applicativo che ne fa richiesta (COPIA);
- Accesso diretto alle tabelle di SIGLA attraverso una connessione al DB di SIGLA (ACCESSO_DB);
- Accesso indiretto alle tabelle di SIGLA tramite un utente di database che abbia i privilegi di lettura all’utente database di SIGLA (UTENTE_DB);
- Utilizzo di Web-Services (WEB SERVICES);
- Utilizzo dei REST (REST).
Si è proceduto ad una attenta analisi delle implementazioni da realizzare rispetto ai requisiti richiesti e, come si evince dalla matrice sottostante, la scelta è ricaduta sui REST in quanto tutti i requisiti vengono soddisfatti.
| COPIA | ACCESSO_DB | UTENTE_DB | WEB SERVICES | REST | |
|---|---|---|---|---|---|
| Tempo Reale | X | X | X | X | |
| Abilitazioni | X | X | |||
| Velocità | X | X | X | X | |
| Facilità | X | X | X | X | |
| Innovazione Tecnologica | X | ||||
| Rapida Implementazione | X | X | X | ||
| Sicurezza | X | X | |||
| Stabilità | X | X | X | X | X |
8.6. Web 2.0 e REST¶
Il web 2.0 ha modificato il modo di progettare applicazioni web: per lo scambio di informazioni tra applicazioni inizialmente ci si è affidati al paradigma architetturale SOA e ai Web Service [1], definito dal W3C come “un sistema software disegnato per supportare l'interoperabilità tra più macchine che interagiscono tra di loro su una rete”. L'interazione tra client e server è effettuata tramite delle invocazioni a procedure remote. Per scambiarsi informazioni su come debbano essere invocate queste procedure remote, si utilizzano nuovi protocolli: SOAP e WSDL. Il World Wide Web, però, è un insieme di risorse che gli utenti utilizzano. Allora, perché utilizzare un modello basato sui servizi per gestire Risorse quando il Web è già fatto di Risorse? Roy Fielding ha risposto a questa domanda disegnando un nuovo paradigma architetturale che pone al centro le “Risorse”: REST.
Questo paradigma ci induce a considerare le applicazioni come un insieme di risorse da gestire.
Viene riportato un estratto della tesi di dottorato di Roy Fielding [2] che descrive il paradigma REST:
The Representational State Transfer (REST) style is an abstraction of the architectural elements within a distributed hypermedia system. REST ignores the details of component implementation and protocol syntax in order to focus on the roles of components, the constraints upon their interaction with other components, and their interpretation of significant data elements. It encompasses the fundamental constraints upon components, connectors, and data that define the basis of the Web architecture, and thus the essence of its behavior as a network-based application. […]
REST emphasizes scalability of component interactions, generality of interfaces, independent deployment of components, and intermediary components to reduce interaction latency, enforce security, and encapsulate legacy systems. I describe the software engineering principles guiding REST and the interaction constraints chosen to retain those principles, contrasting them to the constraints of other architectural styles.
8.6.1. Il modello ROA¶
Il modello ROA è un’architettura software ispirata ai principi REST. Usare il modello ROA significa mettere al centro il concetto di “risorsa”, utilizzando il protocollo HTTP come mezzo per accedervi. HTTP ha già tutto ciò che occorre per identificare una risorsa e indicare una modalità di utilizzo, quindi per richiedere una risorsa basta riferirsi ad essa con l'apposito metodo HTTP GET.
Il concetto di risorsa
Una risorsa è una entità a sé stante, che può essere memorizzata in un computer come un documento, un'immagine, una riga di un database o comunque una stringa di bit. Una risorsa, per essere considerata tale, deve permettere che ci si possa riferire ad essa. Il riferimento a risorse avviene mediante URI [3]. Per essere definita tale, una risorsa deve avere almeno un URI; in caso contrario, non potremo identificarla e quindi non potrebbe essere catalogata come risorsa.
Gli URI devono essere descrittivi: leggendo un URI deve risultare facilmente interpretabile la richiesta che si sta effettuando.
L’architettura orientata alle risorse
L’architettura ROA è l’insieme di quattro aspetti:
- Cos’è una risorsa;
- Cos’è un URI;
- Cosa rappresenta una risorsa;
- Quali sono le relazioni tra le risorse;
e di quattro proprietà:
- Addressability;
- Statelessness;
- Connectedness;
- Uniform Interface.
Addressability:
Un’applicazione è considerata addressable quando espone aspetti rilevanti dei dati attraverso Risorse. Esse sono identificate tramite URL, possiamo richiedere informazioni sempre più specifiche modificando la parte finale del path di una URL. Ciò si può fare quando le risorse sono correlate tra loro, e specializzare un URL significa contemporaneamente scendere ad un livello più specifico nella nostra gerarchia di risorse.
Statelessness:
REST si muove sul protocollo HTTP che è un protocollo stateless. L'esigenza di avere un protocollo stateless ci dà un enorme guadagno in scalabilità, poiché il server non deve associare più richieste una all'altra per capirle ma può utilizzarle una alla volta e poi deallocare le risorse. Questo permette l'implementazione di una struttura atta a garantire l'HA, ovvero un'alta affidabilità del servizio.
Connectedness:
Per connectedness intendiamo la possibilità di avere collegamenti esterni. Molti utenti non hanno la possibilità di digitare gli URL per accedere alle risorse, quindi un'applicazione ben formata dovrebbe, a partire da un qualunque punto, poter arrivare ad accedere a qualunque risorsa sul web, quindi in questo senso il web è connected.
Uniform Interface:
Un'interfaccia uniforme è data proprio dal protocollo HTTP. Uniforme perché HTTP definisce dei metodi standard da utilizzare e un modo omogeneo per scambiarsi le informazioni.
8.6.2. Il protocollo HTTP¶
HTTP è un protocollo che si occupa del trasferimento di ipertesti da un host ad un altro. Il protocollo HTTP (considerando lo stack protocollare) si trova subito sopra il protocollo TCP, ciò garantisce ad HTTP una connessione sicura tra client e server. E' un protocollo “stateless”, ciò indica che ogni richiesta ha tutto, e solo, ciò che occorre per essere servita. Dopo che la richiesta è stata servita la connessione viene chiusa, e le risorse usate deallocate. Le risorse vengono identificate tramite un URI che le definisce univocamente sul server. Il protocollo HTTP definisce:
- I tipi di messaggi scambiati, per esempio, messaggi di richiesta e messaggi di risposta;
- La sintassi dei vari tipi di messaggio;
- Il significato dell'informazione nei campi;
- Le regole per determinare quando e come un processo invia o risponde a messaggi;
Ogni transazione HTTP consiste di una richiesta da parte del client e una risposta da parte del server che generalmente _e in ascolto sulla porta 80 usando il protocollo TCP a livello di trasporto. Nel caso dell'HTTP, un browser web implementa il lato client e un server web ne implementa il lato server, l'host che inizia la sessione è etichettato come client. In figura è evidenziato come avviene la connessione TCP tra Client e Server.
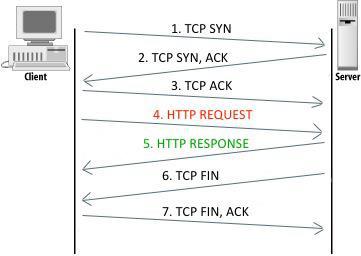
Fig. 8.1 Connessione TCP tra Client e Server
Quando accediamo a una risorsa tramite una URI e HTTP, viene specificata anche l'azione da eseguire su tale risorsa che viene definita utilizzando un metodo HTTP.
| Metodo | Azione |
|---|---|
| GET | Recupera una risorsa identificata da un URI |
| POST | Invia la risorsa al server, aggiorna la risorsa nella posizione individuata dall’URI |
| PUT | Invia una risorsa al server, memorizzandola nella posizione individuata dall’ URI |
| DELETE | Elimina una risorsa identificata da un URI |
| TRACE | Traccia una richiesta, visualizzando come viene trattata dal server |
| OPTIONS | Richiede l'elenco dei metodi permessi dal server |
HTTP si basa su un meccanismo di richiesta/risposta. E’ possibile distinguere due tipi di messaggi:
Messaggio di Richiesta
Questo tipo di messaggio viene mandato dal client verso il server ed è composto da (Figura 1.1):
- Request Line, costituita da:
- Il metodo richiesto;
- L'URI che identifica l'oggetto della richiesta;
- La versione HTTP utilizzata per la comunicazione.
- Request Headers, è composto da un insieme di informazioni aggiuntive sulla richiesta e/o il client (host, sistema operativo, browser che effettua la richiesta, lunghezza della richiesta, ecc.)
- Body, sono delle informazioni non obbligatorie che possono essere inviate al server.
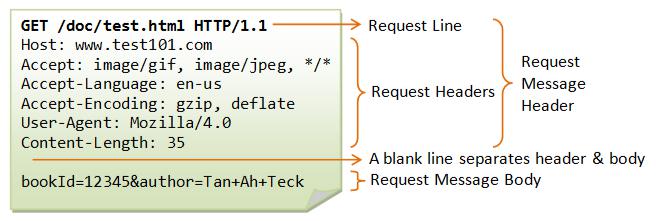
Fig. 8.2 Esempio di richiesta HTTP
Messaggio di risposta
Una volta che il server ha ricevuto dal client una richiesta HTTP, effettua le operazioni necessarie a soddisfarla ed invia una risposta al client. Il messaggio di risposta è di tipo testuale ed è composto da:
- Status Line che contiene la versione del protocollo, l’ID stato che indica il risultato della richiesta e il messaggio di stato corrispondente.
- Headers line - È composto da un insieme di linee non obbligatorie che permettono di dare delle informazioni supplementari sulla risposta e/o il server.
- Body - Contenuto della risposta che contiene le informazioni necessarie per considerare soddisfatta la richiesta.
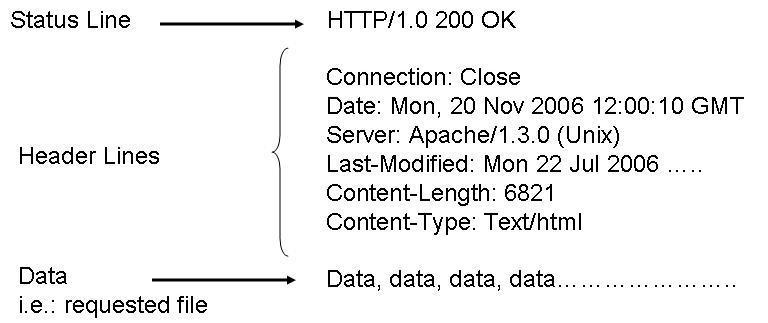
Fig. 8.3 Esempio di messaggio di risposta HTTP
8.6.3. HTTP e ROA¶
REST nella sua implementazione cerca di essere il più semplice possibile. Il Web è nato sul protocollo HTTP, che ha già tutto ciò che occorre per fare web. Si tratta solo di ridefinire qualcosa e di utilizzarlo per ciò per cui è nato. Le risorse vengono identificate tramite un URI che le definisce univocamente sul server. Il protocollo HTTP riveste l'applicazione ROA di un'interfaccia uniforme. Per richiedere una risorsa si utilizzerà sempre lo stesso metodo GET, qualunque sia il tipo di risorsa da recuperare. Inoltre quando il server invia una risorsa al client deve comunicare ad esso anche il tipo MIME, così quest'ultimo può capire che tipo di dato è contenuto nella risposta e interpretarlo correttamente.
8.6.4. SERVLET¶
Una servlet è una componente applicativa server-side sviluppata in Java che risponde direttamente alle richieste WEB. Sono scritte interamente in Java e permettono di separare completamente la logica dall'applicazione, consentendo di dividere i lavori. In sintesi una servlet è lo strato applicativo lato server che intercetta l'oggetto request proveniente dal mondo web, provvede alla logica applicativa e invia al client che ne ha fatto richiesta l’oggetto response che contiene il risultato della richiesta. Per essere invocata da un browser la Servlet deve essere mappata su un URL, quindi per l'utente non è altro che una risorsa da invocare. La Servlet fa il dispatching della request ad una vista che si occupa di formattare il tutto in XML e quindi in un formato standard in modo da poter effettuare una richiesta Ajax.
L'oggetto Request permette di accedere alle informazioni di intestazione del protocollo HTTP oppure ai parametri passati nei form sia tramite GET che tramite POST. Il server può facilmente leggere al momento della richiesta (oltre agli input) i dati quali metodo HTTP utilizzato, porta o ip del client o del server e altro. L'oggetto Response permette di inviare i risultati dell'esecuzione al client.
Le Servlet quindi nell’architettura del Pattern MVC permettono di implementare la parte Controller.
Il ciclo di vita di una servlet è formato da tre passi fondamentali:
- Init(): segna la nascita di una servlet, è un metodo richiamato una sola volta e che si occupa dell'inizializzazione delle risorse;
- Service(): si occupa di servire tutte le richieste che arrivano;
- Destroy(): segna la fine del server, si occupa di memorizzare tutte le informazioni utili ad un prossimo caricamento, e di deallocare tutte le risorse.
8.7. Rappresentazione delle risorse¶
Per rappresentazione si intende una descrizione dello stato corrente di una risorsa che inviata dal Web Service al client in vari formati. Gli standard più comuni di rappresentazioni delle risorse per le richieste HTTP sono XML e JSON perché rappresentano il modo più semplice da implementare lato server ma anche la più facile da utilizzare per un client.
8.7.1. JSON¶
JSON [8], acronimo di JavaScript Object Notation, è un formato adatto all'interscambio di dati fra applicazioniclient-server. Il suo uso tramite JavaScript è particolarmente semplice, infatti l'interprete
- in grado di eseguirne il parsing tramite una semplice chiamata alla funzione eval(). La sua popolarità nel mondo web è aumentata progressivamente in considerazione dell’elevato utilizzo di JavaScript nelle applicazioni WEB.
I tipi di dati supportati da questo formato sono:
- booleani (true e false);
- stringhe racchiuse da doppi apici (");
- array (sequenze ordinate di valori, separati da virgole e racchiusi in parentesi quadre []);
- array associativi (sequenze coppie chiave-valore separate da virgole racchiuse in parentesi graffe);
- interi, reali, virgolamobile;
- null.
La facilità nell’utilizzo ne ha determinato una rapida diffusione anche con altri linguaggi quali, per esempio: C,C#,Delphi,Java,JavaScript,Perl,PHP,Python.
8.8. Vantaggi di REST¶
Il principale vantaggio che si ottiene utilizzando il paradigma REST è l'estrema semplicità della nostra applicazione; utilizza infatti solo protocolli leggeri, in pratica l'unico protocollo di livello applicazione che utilizza è HTTP. Questo comporta sia vantaggi di tipo tecnologico (il non dover essere legati a tecnologie particolari a volte anche commerciali), sia vantaggi in termini di peso delle request le quali sono molto più brevi. Inoltre, l'implementazione in Java non significa altro che la scrittura e l'esecuzione di una semplice classe. Questo significa che per il server è un'applicazione molto leggera e che può essere eseguita su un qualunque hardware su cui si può installare una JVM compatibile con le classi utilizzate. Anche i client sono molto versatili. Infatti un client può essere scritto in un qualunque linguaggio di programmazione, può essere ad interfaccia grafica o a linea di comando e soprattutto, se scritto anch'esso in Java, può essere eseguito su qualunque sistema. Il client deve solo conoscere l'XML ed avere la possibilità di accedere a risorse disponibili sul web.
8.8.1. Implementazione di OPEN SIGLA¶
L’implementazione di Open SIGLA è stata realizzata implementando il paradigma REST all’interno di SIGLA per permettere l’invocazione di URL che forniscano le informazioni richieste dai vari applicativi. In particolare lo sviluppo ha riguardato:
- La creazione di un file xml contenente le informazioni relative alle diverse consultazioni previste con le relative configurazioni e parametrizzazioni;
- La creazione di una Classe Servlet che risponde alle varie richieste effettuate dai client dal nome RESTServlet:
package it.cnr.contab.util.servlet;
import it.cnr.contab.config00.ejb.Unita_organizzativaComponentSession;
import it.cnr.contab.config00.sto.bulk.Unita_organizzativaBulk;
import it.cnr.contab.utente00.nav.ejb.GestioneLoginComponentSession;
import it.cnr.contab.utenze00.bp.CNRUserContext;
import it.cnr.contab.utenze00.bp.RESTUserContext;
import it.cnr.contab.utenze00.bulk.AssBpAccessoBulk;
import it.cnr.contab.utenze00.bulk.CNRUserInfo;
import it.cnr.contab.utenze00.bulk.UtenteBulk;
import it.cnr.contab.utenze00.ejb.AssBpAccessoComponentSession;
import it.cnr.contab.util.servlet.JSONRequest.Clause;
import it.cnr.contab.util.servlet.JSONRequest.OrderBy;
import it.cnr.jada.action.ActionMapping;
import it.cnr.jada.action.ActionMappings;
import it.cnr.jada.action.ActionMappingsConfigurationException;
import it.cnr.jada.action.ActionPerformingError;
import it.cnr.jada.action.ActionUtil;
import it.cnr.jada.action.AdminUserContext;
import it.cnr.jada.action.BusinessProcess;
import it.cnr.jada.action.BusinessProcessException;
import it.cnr.jada.action.HttpActionContext;
import it.cnr.jada.bulk.OggettoBulk;
import it.cnr.jada.bulk.UserInfo;
import it.cnr.jada.comp.ApplicationException;
import it.cnr.jada.comp.ComponentException;
import it.cnr.jada.persistency.sql.CompoundFindClause;
import it.cnr.jada.util.OrderConstants;
import it.cnr.jada.util.action.ConsultazioniBP;
import java.io.File;
import java.io.IOException;
import java.io.PrintWriter;
import java.io.StringWriter;
import java.rmi.RemoteException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Hashtable;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.StringTokenizer;
import javax.ejb.EJBException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.xml.bind.DatatypeConverter;
import org.codehaus.jackson.JsonFactory;
import org.codehaus.jackson.JsonGenerationException;
import org.codehaus.jackson.JsonGenerator;
import org.codehaus.jackson.map.JsonMappingException;
import org.codehaus.jackson.map.ObjectMapper;
import org.codehaus.jackson.map.SerializationConfig;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.google.gson.Gson;
import com.google.gson.JsonParser;
public class RESTServlet extends HttpServlet{
private static final long serialVersionUID = 1L;
private List<String> restExtension;
private File actionDirFile;
private ActionMappings mappings;
private String COMMAND_POST = "doRestResponse", COMMAND_GET = "doRestInfo", ACTION_INFO = "/info";
private static final Logger logger = LoggerFactory.getLogger(RESTServlet.class);
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
execute(req, resp, COMMAND_POST);
}
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
execute(req, resp, COMMAND_GET);
}
protected void execute(HttpServletRequest req, HttpServletResponse resp, String command) throws ServletException, IOException {
resp.setContentType("application/json");
String s = req.getServletPath();
String authorization = req.getHeader("Authorization");
logger.info("RequestedSessionId: "+req.getRequestedSessionId() + ".RemoteAddr: "+req.getRemoteAddr() + ". RemoteHost:"+req.getRemoteHost()+ ". RemotePort: "+req.getRemotePort());
logger.info("RequestedSessionId: "+req.getRequestedSessionId() + ".Action: "+s + ". Command: "+command + ". Authorization:"+authorization);
logger.info("RequestedSessionId: "+req.getRequestedSessionId() + ".ContentType: "+req.getContentType() + ". Encoding:"+req.getCharacterEncoding()+ ". QueryString: "+req.getQueryString());
logger.info("RequestedSessionId: "+req.getRequestedSessionId() + ".ServerName: "+req.getServerName()+". ServerPort:"+req.getServerPort()+".URI: "+req.getRequestURI());
String extension = s.substring(s.lastIndexOf("."));
if(!restExtension.contains(extension))
throw new ServletException("Le actions devono terminare con \\""+restExtension +"\"");
s = s.substring(0, s.length() - extension.length());
if (s.equals(ACTION_INFO)){
if (command.equals(COMMAND_GET)) {
searchForInfo(req, resp);
} else {
throw new ServletException("Non è possibile avere le informazioni sui servizi con il comando POST");
}
} else {
ActionMapping actionmapping = mappings.findActionMapping(s);
if(actionmapping == null)
throw new ServletException("Action not found ["+s+"]");
UtenteBulk utente = null;
try {
if (actionmapping.needExistingSession())
utente = authenticate(req, resp);
if (utente != null \|\| !actionmapping.needExistingSession()) {
JSONRequest jsonRequest = null;
HttpActionContext httpactioncontext = new HttpActionContext(this, req,resp);
httpactioncontext.setActionMapping(actionmapping);
if (command.equals(COMMAND_POST)) {
jsonRequest = new Gson().fromJson(new JsonParser().parse(req.getReader()), JSONRequest.class);
if (actionmapping.needExistingSession()) {
httpactioncontext.setUserContext(getContextFromRequest(jsonRequest, utente.getCd_utente(), httpactioncontext.getSessionId(), req));
httpactioncontext.setUserInfo(getUserInfo(utente, (CNRUserContext)httpactioncontext.getUserContext()));
} else {
httpactioncontext.setUserContext(new RESTUserContext());
httpactioncontext.setUserInfo(getUserInfo(utente, (CNRUserContext)httpactioncontext.getUserContext()));
}
}
try {
BusinessProcess businessProcess;
if (req.getParameter("bpName") != null)
businessProcess = mappings.createBusinessProcess(req.getParameter("bpName"), httpactioncontext);
else
businessProcess = mappings.createBusinessProcess(actionmapping, httpactioncontext);
logger.info("RequestedSessionId: "+req.getRequestedSessionId() + ".Business Process: "+businessProcess.getName());
if (command.equals(COMMAND_POST)) {
Boolean isEnableBP = false;
if (actionmapping.needExistingSession())
isEnableBP = loginComponentSession().isBPEnableForUser(httpactioncontext.getUserContext(), utente, CNRUserContext.getCd_unita_organizzativa(httpactioncontext.getUserContext()), businessProcess.getName());
if ((actionmapping.needExistingSession() && !isEnableBP) \|\| !(businessProcess instanceof ConsultazioniBP)) {
resp.setStatus(HttpServletResponse.SC_UNAUTHORIZED);
resp.getWriter().append("{\"message\" : \\"Utente non abilitato ad eseguire la richiesta!\"}");
return;
}
ConsultazioniBP consBP = ((ConsultazioniBP)businessProcess);
if (jsonRequest != null && jsonRequest.getClauses() != null) {
CompoundFindClause compoundFindClause = new CompoundFindClause();
for (Clause clause : jsonRequest.getClauses()) {
compoundFindClause.addClause(clause.getCondition(), clause.getFieldName(), clause.getSQLOperator(), clause.getFieldValue());
}
consBP.setFindclause(compoundFindClause);
}
consBP.setIterator(httpactioncontext, consBP.search(httpactioncontext, consBP.getFindclause(), (OggettoBulk) consBP.getBulkInfo().getBulkClass().newInstance()));
parseRequestParameter(req, httpactioncontext, jsonRequest, consBP);
}
httpactioncontext.setBusinessProcess(businessProcess);
req.setAttribute(it.cnr.jada.action.BusinessProcess.class.getName(), businessProcess);
httpactioncontext.perform(null, actionmapping, command);
} catch (ActionPerformingError actionperformingerror) {
throw new ComponentException(actionperformingerror.getDetail());
} catch(RuntimeException runtimeexception){
logger.error("RuntimeException", runtimeexception);
throw new ComponentException(runtimeexception);
} catch (BusinessProcessException e) {
logger.error("BusinessProcessException", e);
throw new ComponentException(e);
} catch (InstantiationException e) {
logger.error("InstantiationException", e);
throw new ComponentException(e);
} catch (IllegalAccessException e) {
logger.error("IllegalAccessException", e);
throw new ComponentException(e);
}
}
logger.info("RequestedSessionId: "+req.getRequestedSessionId() + ".End");
} catch (ComponentException e) {
logger.error("ComponentException", e);
resp.setStatus(HttpServletResponse.SC_INTERNAL_SERVER_ERROR);
Gson gson = new Gson();
Map<String, String> exc_map = new HashMap<String, String>();
exc_map.put("message", e.toString());
exc_map.put("stacktrace", getStackTrace(e));
resp.getWriter().append(gson.toJson(exc_map));
}
}
}
Tecnicamente quindi una servlet non è altro che una classe che estende la classe javax.servlet.http.HttpServlet ed implementa l'interfaccia javax.servlet.Servlet.
Questo fa sì che possiamo, e dobbiamo, ridefinire due funzioni:
- doGet viene invocata quando viene richiesta la servlet con metodo HTTPGET;
- doPost viene invocata quando viene richiesta la servlet con metodo HTTP POST.
Entrambe le funzioni ricevono come parametri la request (ossia la richiesta che è stata fatta dal client) e la response (che rappresenta la risposta che dovrà essere inviata al client). Come abbiamo già detto, una Servlet deve gestire il Controller, questo può essere visto come il “cuore” dell'intelligenza dell'applicazione. Lo scopo di una Servlet è recuperare tutti i dati inviati dall'utente, validarli, e se tutto è corretto eseguire una sequenza di operazioni.
Per OPEN SIGLA, dopo aver effettuato alcuni controlli formali sulla request, abbiamo previsto che al metodo HTTP GET corrispondono una serie di informazioni che documentano i vari Servizi REST esistenti, mentre al metodo HTTP POST corrisponde il ritorno al client dei dati amministrativo-contabili di SIGLA richiesti.
8.9. OPEN SIGLA: HTTP GET¶
Invocando il metodo HTTP GET in OPEN SIGLA è possibile avere la documentazione dei
Servizi REST accessibili. In particolare:
- Attraverso la chiamata a info.json si possono avere le informazioni di tutti i servizi REST presenti in OPEN SIGLA con i relativi dettagli tecnici quali: nome del servizio REST, descrizione breve del servizio, la modalità di accesso e le relative autorizzazioni.
Esempio:
GET http://testX.si.cnr.it:8180/SIGLA/info.json?proxyUrl=info.json
Ed ecco la risposta fornita da OPEN SIGLA:
{
"totalNumItems":2,
"maxItemsPerPage":0,
"activePage":0,
"elements": [
{
"action":"/ConsTerzoAction",
"descrizione":"Servizio REST per i Terzi",
"accesso":"CONSTERZOREST",
"authentication":"true"
},
{
"action":"/ConsPDGGAreaAction",
"descrizione":"Consultazione PdG Gestionale Spese per Area/Istituto",
"accesso":"CONSPDGGAREASPE",
"authentication":"true"
}
]
}
- Attraverso la chiamata al singolo servizio REST si potranno avere
- tutte le informazioni tecniche relative ai dettagli delle informazioni che saranno rese disponibili ed in particolare per ciascun attributo: nome, label, tipo di dato, lunghezza massima, obbligatorierà.
Esempio:
GET http://testX.si.cnr.it:8180/SIGLA/ConsTerzoAction.json?proxyUrl=ConsTerzoAction.json
Ed ecco la risposta fornita da OPEN SIGLA:
{
"title":"Terzo",
"fields":[
{
"property":"cd_terzo",
"label":"Codice",
"name":"cd_terzo",
"inputType":"TEXT",
"maxLength":0,
"inputSize":0,
"nullable":true,
"propertyType": "java.lang.Integer"
},
{
"property":"anagrafico.cd_anag",
"label":"Anagrafica",
"name":"cd_anag",
"inputType":"TEXT",
"maxLength":0,
"inputSize":0,
"nullable":true,
"propertyType":"java.lang.Integer"
},
{
"property":"denominazione_sede",
"label":"Denominazione",
"name":"denominazione_sede",
"inputType":"TEXT",
"maxLength":0,
"inputSize":0,
"nullable":true,
"propertyType":"java.lang.String"
},
{
"property":"anagrafico.codice_fiscale",
"label":"Codice Fiscale",
"name":"codice_fiscale_anagrafico",
"inputType":"TEXT",
"maxLength":0,
"inputSize":0,
"nullable":true,
"propertyType":"java.lang.String"
},
{
"property":"anagrafico.partita_iva",
"label":"Partita IVA",
"name":"partita_iva_anagrafico",
"inputType":"TEXT",
"maxLength":0,
"inputSize":0,
"nullable":true,
"propertyType":"java.lang.String"
},
{
"property":"dt_fine_rapporto",
"label":"Fine rapp.",
"name":"dt_fine_rapporto",
"inputType": "TEXT",
"maxLength":0,
"inputSize":0,
"nullable":true,
"propertyType":"java.sql.Timestamp"
},
{
"property":"anagrafico.descrizioneAnagrafica",
"label":"Anagrafica",
"name":"descrizioneAnagrafica",
"inputType":"TEXT",
"maxLength":0,
"inputSize":0,
"nullable":false,
"propertyType":"java.lang.String"
},
{
"property":"anagrafico.ti_italiano_estero_anag",
"label":"Italiano/<BR>Estero",
"name":"italianoEstero",
"inputType":"ROTEXT",
"maxLength":0,
"inputSize":0,
"nullable":true,
"propertyType":"java.lang.String"
}
]
}
Si noti la semplicità di interpretazione della risposta in formato JSON.
8.10. OPEN SIGLA: HTTP POST¶
Nel caso di chiamata del metodo HTTP POST l’implementazione effettua le seguenti operazioni:
- Verifica di esistenza del Servizio REST di consultazione di SIGLA;
- Verifica di abilitazione dell’utente che sta richiedendo il servizio rispetto alle informazioni richieste;
- Chiamata alla BusinessLogic di SIGLA per il recupero delle informazioni richieste, filtrate per il CDR e per l’utente che ne ha effettuato la richiesta;
- Preparazione della response in formato JSON con i risultati richiesti.
Ecco un esempio di chiamata del metodo POST:
Authorization Basic bWlzc2lvbmk6TTE1NTEwTjE=
POST http://testX.si.cnr.it:8180/SIGLA/ConsTerzoAction.json?proxyUrl=ConsTerzoAction.json
{
"activePage":0,
"maxItemsPerPage":10,
"clauses":[
{
"condition":"AND",
"fieldName":"anagrafico.codice_fiscale",
"operator":"=",
"fieldValue":"GSPGFR76E31F839Z"
}
],
"context":{
"esercizio":2016,
"cd_unita_organizzativa":"999.000",
"cd_cds":"999",
"cd_cdr":"999.000.000"
}
}
Ed ecco la risposta fornita da OPEN SIGLA:
{
"totalNumItems":1,
"maxItemsPerPage":10,
"activePage":0,
"elements":[
{
"cd_terzo": 184076,
"cd_anag" : 174071,
"denominazione_sede" : "GASPARRO GIANFRANCO",
"codice_fiscale_anagrafico":"GSPGFR76E31F839Z",
"partita_iva_anagrafico":null,
"dt_fine_rapporto":null,
"descrizioneAnagrafica":"GIANFRANCO GASPARRO",
"italianoEstero":"I"
}
]
}
Si noti come nella chiamata al servizio è possibile indicare il numero massimo di righe da restituire per poter permettere la paginazione nel caso di un numero elevato di dati presenti.
OPEN SIGLA: High Availability
Quando si parla di alta affidabilità del servizio si intende la possibilità di poter fermare ogni singolo componente per permettere aggiornamenti, cambi di configurazioni, manutenzione hardware e software senza dover interrompere il servizio e poterlo fornire in continuazione. Grazie alle caratteristiche dei protocolli di trasporto e dell'applicazione, descritte fino ad ora, stato possibile implementare il servizio Open Sigla su un'architettura in grado di garantire efficienza ed alta affidabilità. Tale architettura è composta dai componenti:
- Firewall: fornisce l'accesso agli utenti e alle applicazioni di terze parti tramite un indirizzo (Traffic Handler) usato per smistare le richieste a nodi multipli, bilanciandole in base all'origine di provenienza.
- Reverse Proxy: server web (Apache Web Server e ModJK connetctor) [9] configurati per accettare le richieste e smistarle ai server applicativi dove viene erogato il servizio. La funzione di questo tipo di server è quella di:
- Catalogare gli accessi e le richieste alle applicazioni (audit log) in maniera centralizzata inviandole ad un sistema remoto (logserver).
- Distribuire automaticamente il flusso applicativo ai server effettivamente attivi, aggiungendoli e rimuovendoli dinamicamente in base al loro stato.
- Dividere le richieste di tipo specifico (ad esempio i Web Services) solo a particolari gruppi di nodi applicativi. Si possono così suddividere le risorse computazionali per tipologie di carico di lavoro.
- Bilanciare le richieste degli utenti in modo da distribuirle efficientemente tra i nodi di calcolo meno impegnati computazionalmente.
- Mantenere una sessione utente legata ad uno specifico nodo applicativo così da ottimizzare il lavoro del nodo stesso
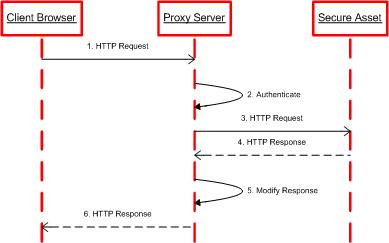
Fig. 8.4 Reverse proxy
In questo diagramma è generalizzato il caso d'uso dei reverse proxy. Secure Asset rappresenta il servizio erogato dai nodi applicativi.
- Application Server: sono i nodi di calcolo basati su Java Virtual Machine e application server Jboss dove viene eseguita l'applicazione e sono serviti dai Reverse Proxy. Possono scalare orizzontalmente, ovvero il loro numero può crescere per far fronte a picchi di richieste da parte degli utenti o delle applicazioni di terze parti.
Per la messa in sicurezza del servizio, la comunicazione di queste componenti avviene su reti (LAN) diverse e fisicamente separate. L'accesso tra loro viene regolato dal firewall perimetrale e vi sono regole di accesso (ACL) specifiche relativamente agli utilizzatori del servizio, alle applicazioni che interagiscono col servizio e al personale autorizzato ad accedere ai sistemi.
Di seguito un diagramma semplificato dell'infrastruttura di HA con un solo servizio oltre a open sigla in evidenza. Anche gli altri servizi, come quello JSON, sono forniti secondo lo stesso principio:
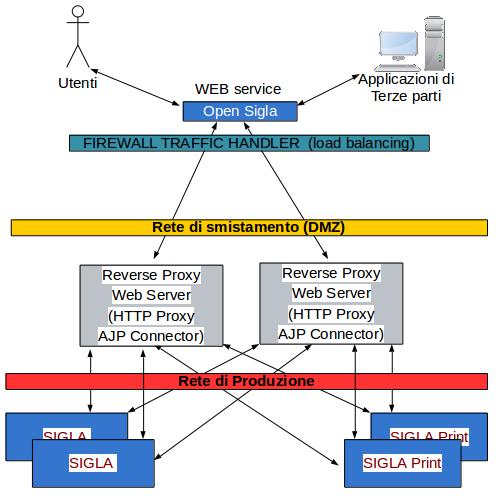
Fig. 8.5 Infrastruttura di HA
Di seguito un esempio di configurazione di un reverse proxy Apache. Esempio estratto dal file worker.properties che definisce i nodi applicativi:
Esempio estratto dal file httpd-vhost.conf che definisce i virtual host con le regole di accesso e puntamento ai worker.
8.11. Conclusioni¶
Nel presente rapporto tecnico è stato presentato il sistema OPEN SIGLA per rendere fruibile a chiunque ne faccia richiesta i dati amministrativo-contabili presenti in SIGLA.
L’implementazione non ha comportato un grande investimento di tempo, in quanto si è provveduto a riutilizzare tutte le consultazioni presenti in SIGLA implementando in aggiunta soltanto la creazione di un file xml di configurazione e la creazione della classe Servlet. Nel caso si volessero avere dati non presenti in nessuna consultazione di SIGLA, sarà necessario sviluppare la parte relativa al recupero delle informazioni richieste e anche in questo caso la modifica non richiederà molto tempo. A fronte di un impegno di tempo e/o risorse limitato, i vantaggi sono molteplici e si possono così sintetizzare:
- eliminazione dell’accesso diretto al database per il recupero delle informazioni, da parte di applicazioni terze;
- disponibilità dei dati in tempo reale;
- accesso ai dati amministrativo-contabili filtrato dalle abilitazioni per utente/funzione;
- nessuna abilitazione aggiuntiva all’accesso dei dati; sono infatti usate le abilitazioni già attive per utente/funzione di SIGLA;
- fruibilità dei dati in un formato facilmente leggibile secondo gli standard più evoluti;
- facilità di implementazione nell’acquisizione dei dati da parte di applicazioni terze;
- documentazione sempre aggiornata dei dati disponibili;
- accesso ai dati senza nessun sovraccarico di risorse per le web-application di esercizio attraverso l’indirizzamento dei servizi REST su una Web-Application dedicata;
- efficienza e continuità di servizio dell'infrastruttura di HA;
- accesso ai dati senza compromettere le operazioni di gestione per gli utenti SIGLA.
Al momento le applicazioni terze che utilizzano OPEN SIGLA sono:
- Gestione Missioni;
- MIA - Monitoraggio Integrato Attività di Ricerca;
- Applicativo integrato di rendicontazione progetti dell’IFAC.
8.11.1. Riferimenti bibliografici e sitografici¶
- Web Service Architecture, W3C, https://www.w3.org/TR/ws-arch/
- Fielding Roy Thomas, Architectural Styles and the Design of Network-based Software Architectures,
University of California, Irvine, 2000, https://www.ics.uci.edu/~fielding/pubs/dissertation/top.htm
- Uniform Resource Identifier: Generic Syntax, RFC 3986, IETF - Internet Engineering Task Force, January 2005, https://tools.ietf.org/html/rfc3986
- Leonard Richardsone e Sam Ruby, RESTful Web Services; O'Reilly, May 2007, https://www.crummy.com/writing/RESTful-Web-Services/RESTful_Web_Services.pdf
- Fielding R., et al., Hypertext Transfer Protocol - HTTP/1.1, RFC 2616, IETF - Internet Engineering Task Force, June 1999, https://tools.ietf.org/html/rfc2616
- Java Servlet Technology, Oracle, http://www.oracle.com/technetwork/java/index-jsp-135475.html
- The DCI Architecture: A New Vision of Object-Oriented Programming - Trygve Reenskaug and James Coplien, March 2009, http://www.artima.com/articles/dci_vision.html
- Introducing JSON, JSON, http://json.org/
- The Apache Tomcat Connectors, http://tomcat.apache.org/connectors-doc/
- Apache HTTP Server, https://httpd.apache.org/docs-project/
Tutti gli indirizzi di rete citati sono stati verificati il 15 luglio 2016
8.11.2. Autori¶
Autore della sezione: Marco Spasiano marco.spasiano@cnr.it
Autore della sezione: Gianfranco Gasparro gianfranco.gasparro@cnr.it
Autore della sezione: David Rossi david.rossi@cnr.it